🏄♂️ Surfing the latent space with Pgvector

This summer, I lost my watch in a hotel in SF. It wasn't worth returning, as a Taxi ride would be more expensive than the watch. Back in Hamburg, I looked for a new watch on Amazon. It doesn't have to be fancy, but it would be nice if it doesn't look too terrible. The brand is secondary for me.
I search for “watch for men” and get this result:
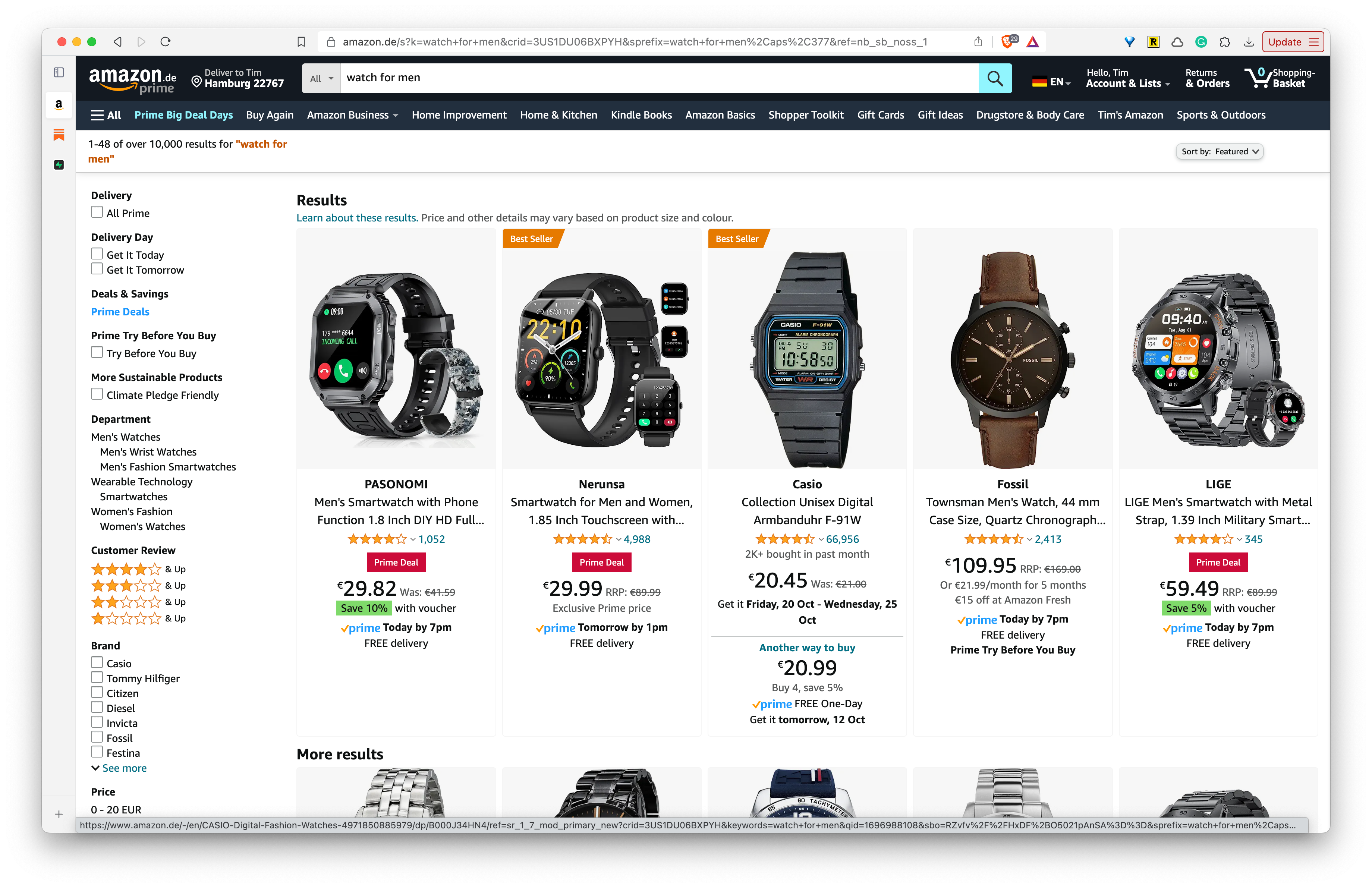
I think it’s needless to say that this page is extremely crowded.
It took me probably 20 minutes of frantic scrolling and paginating to find the style that I’d like.
Amazon has a very spec-focused interface, even for a product like watches, where aesthetics are often more important.
I asked myself: What if I utilize image similarity search to create a better search experience? same.energy created an insanely simple but powerful experience in which I could spend hours. lexica.art later also got inspired by that approach.
What if we apply this to searching for products?
That’s exactly what I’ve done, and you can find the result of this AI UX experiment at same.style.
Instead of having to click through dozens of pages and scroll through a lot of noise, same.style lets you explore styles first, unencumbered by reviews, thickness, band width, country, vendor, diameter, watch movement, embellishment feature, business type, prime, etc. You can collect watches that you like, and it’ll recommend new watches based on that.
However, what if I want to further customize the watches I already selected, while not losing the selected watches? No problem, you can search for selected watches and text at the same time:

How does this work?
I’m using the Contrastive Language-Image Pre-Training (CLIP), which has been created by OpenAI in 2021. It’s one of the first multi-modal models out there, as it brings texts and images into the same vector space.
That means you can turn any text or image into a vector and calculate their distance. You can measure the distance between a picture with a cat, the word “cat” and “dog” and measure its distance. This can even be a simple way to classify an image. You pre-calculate the vector for the word “dog” and for any image you get, you can now calculate the distance.
For the query above with the two watches and the word “blue”, I’m using the following approach:
I first get the embedding vectors for the images of the selected watches and the word “blue”.
Now I’m shifting the image vectors toward the direction of blue through a weighted average. For me, putting a weight of 1 on each image vector and a weight of 0.7 on the text vector worked well. We’re basically “walking” the image vector more in the direction of the text vector in the latent space and then stop on the way.
Based on these new vectors, we now want to construct a query to get watches that are similar to these image vectors. There are 2 options that I saw here.
Take the average of all the vectors — this didn’t yield great results
Split the query and ask for similar images for each vectors — this is the option I went with. So if we want to get 100 watches, we’re getting 50 similar to vector 1, 50 vector 2
Take the results, rerank based on similarity to the text.
Voila, we found blue watches that are similar to the first two watches.
We took an average of vectors — can we just run any distance metric over them? There are 3 common ones, all supported by pgvector:
I chose the Inner Product, as it’s already a distance metric (cosine similarity would need a 1-similarity calculation).
Great, we got that out of the way, but there’s something left. Use The Index, Luke
Since 0.5, pgvector offers 2 indexes:
Pgvector was previously criticized a lot, due to the performance of the IVFFLAT index. However, it added the HNSW, which is the industry standard and used by most vector db vendors. Until Pgvector supported HNSW, I actually used Weaviate because of this reason. I’ll talk another time about why I switched from Weaviate to Pgvector.
I’m using Prisma to run migrations and this is how to add a vector column to your schema:

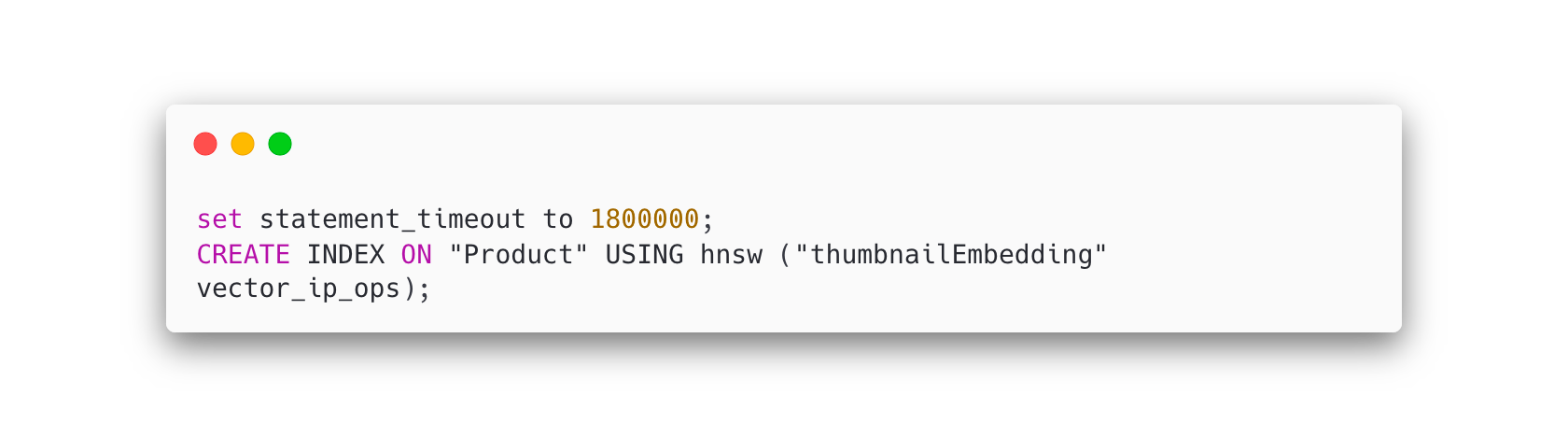
Prisma doesn’t create the index for you - you have to do that yourself. I started adding the index after I already had ~50k vectors in my database. The query was timing out. To fix that, you can increase the statement timeout in the same query like this:
There are a lot of other things going on to make same.style happen, including the scraping infrastructure.
But today, I wanted to focus on how I’ve been surfing the latent space with Pgvector to celebrate the Supabase AI Content Storm they invited me to ;)